
Tutorial
Bookinfo Tutorial
This tutorial will show you how to use Gloo Shot to apply chaos experiments to a simple service mesh app. We will use a slight modification of the familiar bookinfo app from Istio’s sample app repo. We have modified the reviews service to include a vulnerability that can lead to cascading failure. We will use Gloo Shot to detect this weakness.
The Goal
Services should be built to be resilient when dependencies are unavailable in order to avoid cascading failures. In this example, we show how to detect cascading failures: failures where an error in one service disables other services that interact with it. In the diagram below, we show two versions of a reviews service. The version on the top right fails when it does not receive a valid response from the ratings. The version on the bottom right handles the error more gracefully. It still provides review information even though the ratings data is not available.
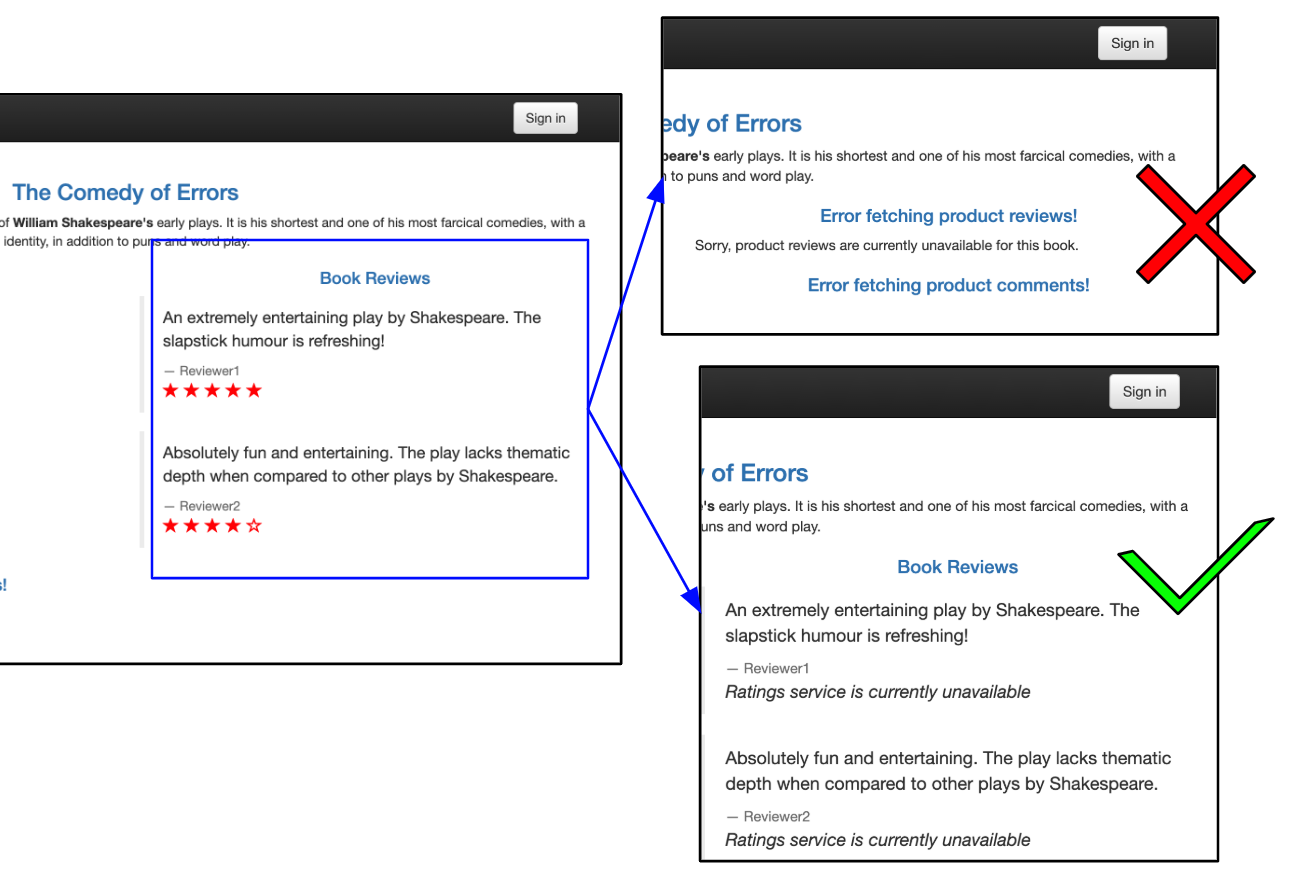
The book info app consists of three services. If the ratings service fails, we do not want it to break the reviews service, as shown in the top-right frame. In a resilient app, the reviews service will continue to work, even if one of its dependencies is unavailable, as shown in the bottom-right frame.
Prerequisites
To follow this demo, you will need the following:
glooshot(download) command line tool, v0.0.5supergloo(download) command line tool, v0.3.18, for simplified mesh management during the tutorial.kubectl(download)- A Kubernetes cluster - minikube will do
Setup
Deploy Gloo Shot
- Gloo Shot can easily be deployed from the command line tool.
First register the Custom Resource Definitions (CRDs) used by Gloo Shot.
This will register the
experiments.glooshot.solo.ioandreports.glooshot.solo.ioCRDsglooshot register
Verify that the CRDs were created:
kubectl get crd | grep glooshotExpect to see output similar to this:
experiments.glooshot.solo.io 2019-06-10T15:31:03Z reports.glooshot.solo.io 2019-06-10T15:34:33ZNext, let’s deploy the Gloo Shot resources.
This will create and populate the
glooshotnamespace.glooshot init
Let’s review what this command is doing:
kubectl get pods -n glooshot -wWhen the initialization is completed, you should see something like this:
kubectl get deployments -n glooshot NAME READY UP-TO-DATE AVAILABLE AGE discovery 1/1 1 1 2m37s glooshot 1/1 1 1 2m36s glooshot-prometheus-alertmanager 1/1 1 1 2m37s glooshot-prometheus-kube-state-metrics 1/1 1 1 2m37s glooshot-prometheus-pushgateway 1/1 1 1 2m37s glooshot-prometheus-server 1/1 1 1 2m37s mesh-discovery 1/1 1 1 2m36s supergloo 1/1 1 1 2m37sThese resources serve the following purposes:
- glooshot manages your chaos experiments
- supergloo and mesh-discovery are from the SuperGloo. Together, they translate experiment specifications into the desired service mesh behavior.
- discovery, from Gloo, finds and lists all the available chaos experiment targets.
- glooshot-prometheus-*, from Prometheus, provides metrics. If you already have Prometheus running it is possible configure Gloo Shot to use your existing instance instead of deploying this one.
Install a service mesh (if you have not already)
Install a service mesh.
- We will use Istio for this tutorial.
We will use SuperGloo to install Istio with Prometheus.
supergloo install istio \ --namespace glooshot \ --name istio-istio-system \ --installation-namespace istio-system \ --mtls=true \ --auto-inject=true
Verify that Istio is ready.
When the pods in the
istio-systemnamespace are ready or completed, you are ready to deploy the demo app.kubectl get pods -n istio-system -w
Provide metric source configuration to Prometheus
Prometheus is a powerful tool for aggregating metrics. To use Prometheus most effectively, you need to tell it where it can find metrics by specifying a list of scrape configs.
Here is an example config for how Istio’s metrics should be handled by Prometheus. As you can see, scrape configs that are both insightful and resource-efficient can be quite complicated. Additionally, managing Prometheus configs for multiple scrape targets can be difficult.
Fortunately, SuperGloo provides a powerful utility for configuring your Prometheus instance in such a way that is appropriate for your chosen service mesh.
By default, glooshot init deploys an instance of Prometheus (this can be disabled).
For best results, you should configure this instance of Prometheus with the metrics that are relevant to your particular service mesh.
We will use the supergloo set mesh stats utility for this.
supergloo set mesh stats \
--target-mesh glooshot.istio-istio-system \
--prometheus-configmap glooshot.glooshot-prometheus-serverNote that we just had to tell SuperGloo where to find the mesh description and where to find the config map that we want to update. SuperGloo knows which metrics are appropriate for the target mesh and sets these on the active prometheus config map. You can find more details on setting Prometheus configurations with SuperGloo here.
Deploy the bookinfo app
Now deploy the bookinfo app to the bookinfo namespace
kubectl create ns bookinfo kubectl label namespace bookinfo istio-injection=enabled kubectl apply -n bookinfo -f https://raw.githubusercontent.com/solo-io/glooshot/master/examples/bookinfo/bookinfo.yamlVerify that the app is ready.
When the pods in the
bookinfonamespace are ready, we can start testing our appkubectl get pods -n bookinfo -w
Let’s access the landing page of our app
kubectl port-forward -n bookinfo deployment/productpage-v1 9080Navigate to http://localhost:9080/productpage?u=normal in your browser.
- You should see a book description, reviews, and ratings - each provided by their respective services.
- Reload the page a few times, notice that the ratings section changes. Sometimes there are no stars, other times red or black stars appear. This is because Istio is load balancing across the four versions of the reviews service. Each reviews service renders the ratings data in a slightly different way.
Let’s use SuperGloo to modify Istio’s configuration such that all reviews requests are routed to the version of the service that has red stars - and an unknown vulnerability!
supergloo apply routingrule trafficshifting \ --namespace bookinfo \ --name reviews-vulnerable \ --dest-upstreams glooshot.bookinfo-reviews-9080 \ --target-mesh glooshot.istio-istio-system \ --destination glooshot.bookinfo-reviews-v4-9080:1Now when you refresh the page, the stars should always be red.
To be clear, there are four different versions of the reviews deployment. We use versions 3 and 4 in this tutorial.
- reviews-v3 is resilient against cascading failures
- reviews-v4 is vulnerable to cascading failures
Create an experiment
Create a simple experiment with
kubectl:- Introduce a fault to the ratings service so that it always returns
500as a response code. - The experiment should expire after 60e seconds if the failure conditions have not been met.
The Prometheus query below must not exceed a value of
0.01scalar(sum(rate(istio_requests_total{ source_app="productpage", response_code="500", reporter="destination", destination_app="reviews", destination_version!="v1" }[1m])))
- Introduce a fault to the ratings service so that it always returns
Execute the command below to create this experiment
cat <<EOF | kubectl apply -f - apiVersion: glooshot.solo.io/v1 kind: Experiment metadata: name: abort-ratings-metric namespace: bookinfo spec: spec: duration: 600s failureConditions: - trigger: prometheus: customQuery: | scalar(sum(rate(istio_requests_total{ source_app="productpage",response_code="500",reporter="destination",destination_app="reviews",destination_version!="v1"}[1m]))) thresholdValue: 0.01 comparisonOperator: ">" faults: - destinationServices: - name: bookinfo-ratings-9080 namespace: glooshot fault: abort: httpStatus: 500 percentage: 100 targetMesh: name: istio-istio-system namespace: glooshot EOFRefresh the page, you should now see a failure: none of the reviews data is rendered
Refresh the page about 10 more times.
Within 15 seconds after the threshold value is exceeded you should see the error go away. The experiment stop condition has been met and the fault that caused this cascading failure has been removed.
- The reason for this is that Prometheus gathers metrics every 15 seconds.
Inspect the experiment results with the following command:
kubectl get exp -n bookinfo abort-ratings-metric -o yamlYou should see something like this:
result: failureReport: comparison_operator: '>' failure_type: value_exceeded_threshold threshold: "0.01" value: "0.45160204631125467" state: Failed timeFinished: "2019-06-10T16:08:39.869280871Z" timeStarted: "2019-06-10T16:08:24.805158537Z"Note that the state reports the experiment has “Failed”. This is because the experiment was terminated because a threshold value was exceeded. If the experiment had been terminiated by a timeout, it would be in state “Succeeded”.
- Experiments that fail, such as this one, indicate that our service is not as robust as we would like.
The experiment also reports the exact value that was observed, which caused the failure. Note that the value is 0.45, which exceeds our limit of 0.01. This is because the metric value may rise above the limit in the time it takes for Prometheus to report the exceeded limit.
Gloo Shot generates reports with each experiment. After an experiment completes, you can review the values that were recorded for each of its metrics throughout the duration of the experiment. Reports are stored in the same namespace and with the same name as the corresoponding experiment
kubectl get reports -n bookinfo abort-ratings-metricYou should see something similar to the following.
- Note that there are three entries, one for each metric measurement.
- The first two values are empty. This reflects how Prometheus reports the absence of any observations of our metric.
- The final value matches the value shown in our experiment’s
result.failureReport.valuefield. Note that the failure condition name is auto generated since we did not provide one in our
experimentspec. A unique name was generated for us in case we had multiple metrics and wanted to associate a result with a metric.failureConditionHistory: - failureConditionName: 0-1560182904805162499 failureConditionSnapshots: - timestamp: "2019-06-10T16:08:29.854217373Z" value: NaN - timestamp: "2019-06-10T16:08:34.853080228Z" value: NaN - timestamp: "2019-06-10T16:08:39.852576785Z" value: 0.45160204631125467
Repeat the experiment on a new version of the app
- Now that we found a weakness in our app, let’s fix it.
- Let’s deploy a version of the app that does not have this vulnerability. Instead of failing when no data is returned from the ratings service, the more robust version of our app will just exclude the ratings content.
In this demo, we happened to already have deployed this version of the app. Let’s use SuperGloo to update Istio so that all traffic is routed to the robust version of the app, as we did above.
kubectl delete routingrule -n bookinfo reviews-vulnerable supergloo apply routingrule trafficshifting \ --namespace bookinfo \ --name reviews-resilient \ --dest-upstreams glooshot.bookinfo-reviews-9080 \ --target-mesh glooshot.istio-istio-system \ --destination glooshot.bookinfo-reviews-v3-9080:1Verify that the new routing rule was applied
- Refresh the page, you should see no errors
Run the following command, you should see
reviews-v3in theglooshotnamespacekubectl get routingrule --all-namespaces
Now let’s execute this experiment again to verify that our app is robust to failure.
This time, we do not expect any failures so we will set a shorter timeout.
We also need to increase the threshold, since we increased our metrics in the last experiment.
Use the following command to create a new experiment:
cat <<EOF | kubectl apply -f - apiVersion: glooshot.solo.io/v1 kind: Experiment metadata: name: abort-ratings-metric-repeat namespace: bookinfo spec: spec: duration: 30s failureConditions: - trigger: prometheus: customQuery: | scalar(sum(rate(istio_requests_total{ source_app="productpage",response_code="500",reporter="destination",destination_app="reviews",destination_version!="v1"}[1m]))) thresholdValue: 0.01 comparisonOperator: ">" faults: - destinationServices: - name: bookinfo-ratings-9080 namespace: glooshot fault: abort: httpStatus: 500 percentage: 100 targetMesh: name: istio-istio-system namespace: glooshot EOFRefresh the page, you should now see content from the reviews service and an error from the ratings service only.
We have made our app more tolerant to failures!
- Even though the ratings service failed, the reviews service continued to fullfill its responsibilities.
Let’s inspect the experiment results:
kubectl get exp -n bookinfo abort-ratings-metric-repeat -o yamlYou should see that the experiment succeeded after having run for the entire time limit.
result: state: Succeeded timeFinished: "2019-05-13T18:03:05.655751554Z" timeStarted: "2019-05-13T18:02:35.650035732Z"